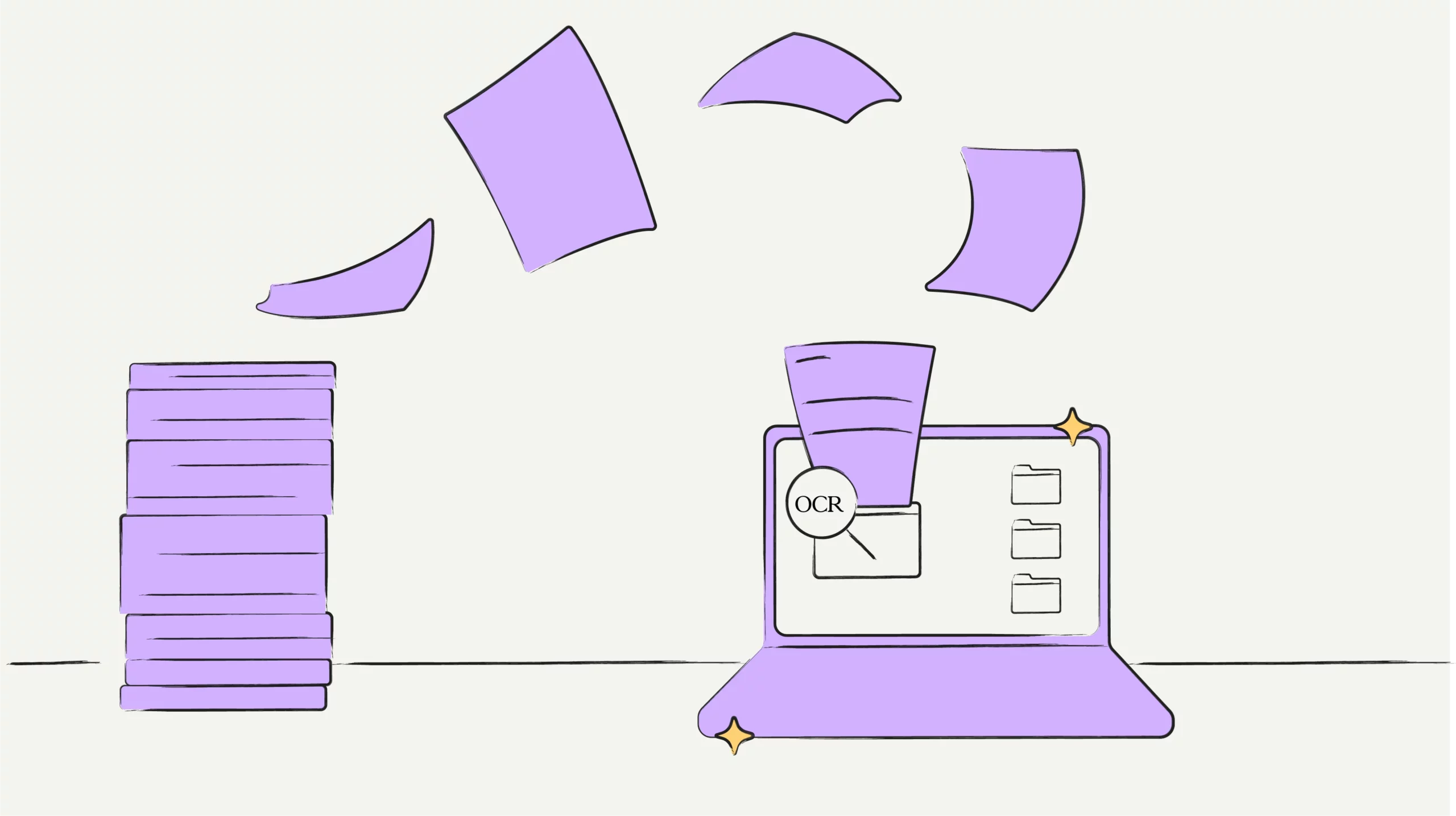
- OCR (optical character recognition) converts scanned contracts and image-based PDFs into machine-readable, searchable text. Without it, legacy contracts are invisible to CLM systems and cannot be tracked, searched, or audited.
- Basic OCR extracts text. It does not understand meaning, flag risk clauses, or categorize obligations. That requires AI layered on top of OCR, what modern platforms call smart OCR or intelligent document processing.
- Organizations managing contracts manually spend an average of $575,000 annually processing 5,000 contracts. OCR-powered contract management software reduces processing time by up to 80% and recovers an estimated 9.2% of contract value lost to manual inefficiency.
Every organization has a contract visibility problem hidden inside a filing cabinet, a network drive, or a legacy document management system. Contracts that exist only as scanned images or printed paper cannot be searched, tracked, or audited by any CLM platform. OCR contract management solves that problem at its source by converting unreadable contract images into structured, machine-readable data before anything else in the contract lifecycle can work.
OCR in contract management is the process of applying optical character recognition technology to contract documents to extract text, identify key fields, and feed structured data into a contract lifecycle management system. Contract OCR is the entry point that determines whether a legacy contract estate becomes a strategic asset or remains a liability buried in an unmanageable archive.
This guide covers what OCR in contract management is, how it works step by step, how OCR compares to AI in contract processing, the measurable ROI organizations achieve from OCR-enabled CLM, the limitations of basic OCR and how smart OCR addresses them, and how to choose OCR software for contract management that performs in the real conditions of your document estate.
What is OCR in contract management?
Optical character recognition (OCR) is a technology that recognizes text embedded in digital image files, scanned documents, and non-searchable PDFs and converts it into machine-readable, editable text. In contract management, OCR is used to digitize contracts that exist only in physical or image format, making them accessible to CLM systems, search engines, compliance tools, and obligation trackers.
Without OCR, a contract stored as a scanned PDF is functionally invisible to software. It has a file name and a file size. It has no searchable text, no extractable metadata, no trackable dates, and no content that a CLM system can analyze or act on. OCR removes that barrier by converting the image into text that software can read, classify, and process.
OCR in contract management operates through integration with artificial intelligence, natural language processing (NLP), and data extraction capabilities. OCR handles the recognition layer. AI handles the classification layer. Together, they convert a pile of scanned agreements into a structured, searchable, trackable contract repository.
OCR is also referred to as OCR data capture when used to extract and structure specific data fields from contract documents, and as OCR data extraction or OCR data services when the output feeds into downstream analytics or CLM platforms. In enterprise contract operations, this process is commonly managed by an OCR data capture consultant or OCR data extraction consultant who configures the extraction rules, validates output accuracy against source documents, and integrates the extracted data into the organization’s contract management workflow.
OCR contract management differs from general document OCR in that the documents being processed have specific structural characteristics: governing law clauses, counterparty identification blocks, payment schedule tables, termination provisions, and renewal date fields. Contract OCR systems are trained or configured to locate and extract these specific fields rather than treating every document as a generic collection of text.
OCR vs AI in contract management: what is the difference?
OCR and AI serve different but complementary functions in contract management. Understanding the distinction is essential when evaluating what a platform can actually do with your contract documents versus what it claims.
| Capability | Basic OCR only | AI-assisted OCR (smart OCR) |
|---|---|---|
| Converts scanned document to text | Yes | Yes |
| Makes contracts keyword-searchable | Yes | Yes |
| Identifies what a clause means | No | Yes (via NLP) |
| Categorizes clauses by type | No | Yes |
| Flags risk provisions automatically | No | Yes |
| Extracts structured metadata fields | Partial (requires custom templates) | Yes (without custom templates) |
| Handles non-standard layouts accurately | Poorly | Accurately |
| Improves accuracy over time | No | Yes (machine learning) |
| Integrates with CLM workflows | Limited | Full native integration |
The concept of “smart OCR contracts” describes a system where OCR handles the text extraction layer and AI handles the classification, risk flagging, and metadata structuring layer. The term “intelligent document processing” (IDP) refers to the same combined approach. AI-assisted OCR produces contract intelligence rather than just digitized text.
OCR is the foundation. AI is what makes the output usable for contract management at scale. A system with OCR but without AI produces text files that someone still has to read and manually enter into fields. A system with AI on top of OCR produces structured contract data that flows directly into review workflows, obligation trackers, and compliance dashboards without human re-entry. When evaluating any OCR for contract management platform, the critical question is not whether the system can read a scanned contract, but whether it can classify what it reads into structured, actionable data automatically.
How OCR contract management works: 7-step process
The contract OCR process follows a defined seven-stage pipeline from raw document input to structured, trackable contract data.
- Contract input. Documents are uploaded in any supported format: scanned PDFs, image files (JPEG, TIFF, PNG), physical paper fed through a scanner, email attachments, or legacy Word documents. Modern OCR systems for contract management accept multi-format batches rather than requiring document-by-document processing.
- Preprocessing. The system scans each document for quality issues: low resolution, skewed orientation, uneven brightness, noise artifacts, or duplicate pages. Preprocessing corrects these issues automatically before character recognition begins, because recognition accuracy is directly dependent on image quality. Documents with severe degradation are flagged for manual review at this stage.
- Segmentation. The system divides each contract into structural components: header blocks, numbered clauses, signature blocks, exhibit tables, and defined term sections. Segmentation allows the OCR engine to apply different recognition settings to different document regions, improving accuracy on mixed-format contracts that combine standard paragraphs with tables, numbered lists, and handwritten annotations.
- Character recognition. The core OCR process identifies individual characters, words, and phrases using pattern recognition, feature extraction, or AI-powered neural network models. Modern contract OCR engines apply multiple recognition passes to ambiguous characters and use legal vocabulary dictionaries to resolve common misreads (for example, distinguishing “0” from “O” in contract identifiers).
- Text conversion and classification. Recognized text is converted to machine-readable format (plain text, structured JSON, or searchable PDF layer) and classified by content type. An AI classification layer maps extracted text to specific contract fields: party names, effective dates, governing law, payment amounts, termination conditions, and renewal provisions. This is the step that separates smart OCR from basic OCR.
- Post-processing. Extracted and classified data is stored in the contract repository, tagged with metadata, linked to the source document, and made available for search, tracking, and reporting. Obligation dates trigger automatic reminder workflows in contract tracking software. Risk flags route documents to the appropriate review queue.
- Review and verification. High-confidence extractions are accepted automatically. Low-confidence extractions (below a defined threshold, typically on handwritten content or degraded scans) are routed to a human reviewer who confirms or corrects the extracted data before it is committed to the contract record. Review rates decrease as the AI model improves on the organization’s specific document types over time.
5 benefits of OCR in contract management
OCR transforms how organizations interact with their contract estate by making previously inaccessible documents functional. The five primary benefits operate across the full contract lifecycle.
- Automated metadata extraction. OCR eliminates the manual data entry required to onboard legacy contracts into a CLM system. Instead of a paralegal spending 90 minutes extracting key dates, party names, and payment terms from each agreement, OCR extracts 30+ contract properties per document automatically. According to Record Nations, employees typically spend 30-40% of their productive time locating information in physical filing systems. OCR converts that time into recoverable capacity.
- Intelligent field identification and tagging. AI-assisted OCR identifies and tags important clauses and terms beyond simple text extraction, enabling contract-level search across an entire portfolio. A legal team can search for every contract with a “limitation of liability” clause below $500,000, every agreement governed by New York law, or every vendor contract with an auto-renewal provision, in seconds rather than weeks of manual review.
- Centralized contract repository. OCR converts contracts stored in physical files, email attachments, shared drives, and legacy systems into a single organized contract repository. This creates a single source of truth for the full contract estate, replacing fragmented storage with a searchable, permissioned, auditable archive.
- Obligation tracking and renewal management. Once key dates are extracted from scanned contracts, contract automation software can generate automatic alerts for renewal windows, expiration dates, payment milestones, and compliance deadlines. Organizations using manual contract tracking miss renewal windows at an average rate that contributes to the 9.2% of annual contract value lost to poor management practices.
- Reduced error and improved compliance. Manual data entry from scanned contracts introduces transcription errors that compound over time: wrong dates in reminder systems, incorrect payment amounts in finance records, missing governing law designations in dispute resolution planning. OCR extraction with AI classification produces consistent, auditable data with error rates measurably lower than manual re-entry across large document volumes.
OCR in contract management: ROI and cost analysis
The financial case for OCR in contract management is driven by two cost categories: the direct cost of manual contract processing and the indirect cost of contract value lost through poor visibility.
Direct cost of manual contract processing. A mid-sized organization managing 5,000 contracts annually, with staff spending an average of 92 minutes per contract on manual data entry and review, dedicates approximately 7,667 staff-hours per year to contract processing alone. At a loaded cost of $75 per hour, that is $575,000 in direct annual labor for a process that OCR and AI complete in under five minutes per document. OCR-powered CLM reduces processing time by up to 80%, recapturing the majority of that cost within the first year of deployment.
Indirect cost of poor contract visibility. According to a study commissioned by DocuSign, organizations lose an average of 9.2% of annual contract value due to missed obligations, renewal lapses, pricing misalignments, and unenforceable terms that were never tracked. For an organization with $10 million in annual contract commitments, that is $920,000 in recoverable value. OCR-enabled CLM makes that value visible and trackable. For finance teams evaluating the most accurate OCR for financial terms extraction from legacy contracts, the accuracy differential between basic OCR (60-75% on degraded documents) and AI-assisted OCR (94%+) represents a material difference in the reliability of financial data extracted from historical agreements, pricing schedules, and payment amendments. This connects directly to revenue leakage that finance audits rarely catch because the source documents are not searchable.
ROI benchmarks from OCR-enabled contract management deployments:
- 80% reduction in contract processing time per document
- 2 hours average savings per contract search and retrieval
- 60% to 95%+ improvement in metadata extraction accuracy (basic OCR to AI-assisted OCR)
- $91 to $183 return for every dollar invested in contract management automation
- 740% first-year ROI reported by healthcare organizations deploying OCR-enabled CLM for legacy contract digitization
Stop re-keying data from scanned contracts into spreadsheets
HyperStart CLM extracts 30+ contract properties from scanned PDFs, image files, and legacy documents with 94% AI accuracy.
Book a DemoOCR limitations in contract management: what basic OCR cannot do
Basic OCR works for clean, standardized documents. Contract portfolios are rarely clean or standardized. Understanding OCR’s specific limitations in contract management contexts is necessary before selecting a solution and setting accuracy expectations.
Inaccurate extraction from complex layouts
Basic OCR engines are calibrated for clean, uniform document formats. Contracts with multi-column layouts, non-standard fonts, tables embedded within paragraphs, watermarks, or degraded scan quality generate character recognition errors that require manual correction before the data is usable. Error rates of 5-15% on non-standard documents are common with basic OCR engines that lack AI preprocessing. In a portfolio of 5,000 contracts, that translates to 250 to 750 contracts with extraction errors that will silently corrupt downstream data if not caught.
No contextual understanding
OCR extracts text. It does not understand what the text means. A basic OCR engine cannot distinguish between a payment due date and a contract start date, between a limitation of liability cap and a minimum order quantity, or between a termination-for-cause clause and a termination-for-convenience clause. Without an AI classification layer, a scanned contract processed through basic OCR produces a text file. The same contract processed through AI-assisted OCR produces structured, categorized, searchable data where each extracted value is mapped to the correct contract field. Legal OCR challenges and solutions center on this gap: the solution is not better character recognition, it is adding the semantic layer that makes extracted text interpretable.
Poor performance with handwritten text and non-standard formats
Handwritten contract amendments, signature annotations, and wet-ink dates are problematic for basic OCR. Legacy contracts from the 1990s and earlier frequently combine typed and handwritten sections. Basic OCR accuracy on purely handwritten text averages 60-75% even with modern engines. AI-trained handwriting recognition reaches 85-90% but requires purpose-built training on legal document handwriting specifically, not general handwriting datasets. For organizations with significant handwritten annotation in their legacy archives, this requires a platform with dedicated legal handwriting models rather than a generic OCR tool.
Limited integration with CLM workflows and analytics
Basic OCR tools output text or a searchable PDF layer. They do not map extracted data to contract fields in a CLM system, trigger workflow events based on extracted dates, or feed obligation data into contract management dashboards. Without deep integration between the OCR extraction layer and the CLM platform, teams are still manually copying extracted text into contract management system fields, replacing one form of manual labor with a slightly faster but equally unreliable one. True OCR contract management requires the OCR output to flow natively into the CLM’s data model without a manual transfer step.
Legal OCR and enterprise OCR: applications by team and industry
OCR requirements differ meaningfully by team function and industry vertical. The documents being scanned, the data fields being extracted, and the downstream systems receiving that data vary enough across contexts that a generic OCR approach produces inconsistent results. Here is how OCR contract management applies across the most common use cases.
Legal OCR for legal operations teams
Legal operations teams use legal OCR to digitize executed contracts, court filings, regulatory correspondence, and legacy agreement archives stored in physical files. Legal OCR accuracy requirements are higher than general document OCR because errors in extracted clause language can affect enforceability assessments, compliance determinations, and litigation strategy. Legal OCR implementations typically include a human review queue for flagged low-confidence extractions, particularly for handwritten annotations on signed documents and for contracts with non-standard numbering conventions. For a comprehensive view of how legal ops teams structure contract digitization programs, see legal operations best practices.
Enterprise OCR for large contract portfolios
Enterprise OCR describes OCR deployed across an organization’s entire contract estate rather than a single department or document type. Enterprise OCR systems process multi-format inputs simultaneously: scanned PDFs, image files, email attachments, legacy Word documents, and fax-generated contracts from older vendor relationships. At enterprise scale, OCR systems must handle 47+ languages, multiple governing law jurisdictions, and varying signature and date formats without requiring per-document template configuration. OCR enterprise deployments also require SOC 2 Type II certification and data residency options for organizations with cross-border data governance obligations. The OCR manager within an enterprise CLM gives legal operations full visibility into extraction status, accuracy flags, and review queue volume across the entire processing pipeline.
OCR for government contracts
Government contract management involves unique document formats that standard OCR engines misread: FAR clause references, GSA schedule attachments, agency-specific addenda, and compliance certifications with structured data in non-standard positions. OCR solutions for government must handle dense regulatory language, numbered clause cross-references, and procurement schedule tables accurately. OCR for government deployments also requires FedRAMP authorization or equivalent security certification for documents containing controlled unclassified information (CUI) or sensitive procurement data. OCR management for government contract portfolios typically includes jurisdiction-specific extraction templates for the most common federal contract formats.
OCR in construction
Construction OCR processes subcontractor agreements, lien waivers, material supply contracts, change orders, and insurance certificates. OCR meaning in construction is primarily about digitizing paper-based site documentation and feeding it into project management and contract tracking systems. Construction contracts frequently include handwritten change order amounts, site manager signatures, and project-specific payment schedules that require AI-assisted handwriting recognition rather than basic character OCR. OCR full form in construction simply refers to optical character recognition applied to construction-specific document types. OCR in construction is especially valuable for identifying disputed payment terms in multi-party project agreements where the paper trail is the only enforceable record.
OCR in real estate
Real estate documents OCR covers lease agreements, purchase contracts, title deeds, easements, and property management contracts. OCR in real estate is particularly valuable for portfolio managers handling hundreds of leases across multiple properties, where key date extraction (lease expiration, rent escalation triggers, renewal options, co-tenancy provisions) must be automated to avoid costly lapses. OCR meaning in real estate and “what is OCR in real estate” refer to the same application: converting paper-based property agreements into searchable, trackable digital records. OCR full form in real estate is identical to the general definition. Operating agreement OCR is a common real estate use case for partnership documents governing multi-owner properties.
OCR document management
OCR document management systems combine OCR extraction with document classification, version control, access permissions, and retention policies. A document management system with OCR allows teams to search across the full text of every contract in the repository, not just file names and metadata tags. OCR document management turns a static file archive into a queryable data layer. Document management OCR and OCR for document management are terms used interchangeably to describe this combined capability. An OCR document management system typically stores extracted data separately from the source document image, allowing full-text search without retrieving the original file for each query.
OCR finance and purchase order OCR
OCR finance applications cover invoice processing, purchase order OCR for matching purchase order terms against contract pricing, financial terms extraction from legacy agreements, and compliance document scanning. OCR in finance is used to surface payment obligations, pricing escalators, credit limits, and penalty clauses from contracts that previously existed only as paper records. Benefits of OCR in finance include: accurate obligation tracking against budgets, automated invoice matching against contracted rates, and audit-ready documentation of historical payment terms. Purchase order OCR specifically extracts line items, unit prices, delivery dates, and authorization signatures from purchase orders for matching against the underlying supply agreements.
OCR for contract management: applications by industry and team
Beyond team-specific applications, OCR in contract management addresses three enterprise-level use cases that apply across industry verticals.
CLM migration and legacy contract onboarding
The most common trigger for OCR investment is a CLM migration: an organization moving from paper-based or email-based contract management to a CLM platform needs to digitize its existing contract estate before the platform can manage it. Without OCR, the legacy archive remains outside the CLM and continues to create blind spots in obligation tracking, renewal management, and compliance reporting. OCR contract digitization during a CLM migration is the difference between a CLM that manages future contracts and one that manages the organization’s entire contractual position.
Compliance monitoring from legacy agreements
Legacy contracts that predate the current CLM system contain obligations, restrictions, and compliance requirements that are invisible to modern contract management tools until they are digitized. OCR extraction during compliance programs surfaces: expired confidentiality terms that are still being honored past their contractual duration, vendor exclusivity clauses that are being violated by new supplier relationships, and regulatory compliance certifications embedded in contract exhibits that have not been renewed. Contract risk management software uses OCR-extracted obligation data to identify these compliance gaps proactively rather than reactively.
Renewal management from scanned contracts
Auto-renewal clauses in legacy contracts that were never tracked create two opposite risks: contracts that renew automatically when the organization wants to exit the relationship, and contracts that expire without renewal when the organization depends on continued service. OCR extraction of renewal dates and notice windows feeds this data into contract automation workflows that generate alerts 60 and 30 days before every renewal decision point. This converts a reactive process (discovering a missed window after the fact) into a proactive one.
Replace your OCR workaround with a system that actually scales
HyperStart combines OCR extraction with AI classification so your legal team gets structured contract data, not just a text file. No custom templates. No manual re-entry.
Book a DemoHow to choose OCR software for contract management
Choosing OCR software for contract management requires evaluating six dimensions. An OCR tool that performs well in a vendor demonstration on clean sample documents may perform poorly on the actual conditions of your contract estate.
- Extraction accuracy on your specific document types. Request a pilot extraction on a representative sample of 50 to 100 of your actual contracts before committing to a platform. Vendor accuracy claims on clean documents are not predictive of accuracy on your legacy archive. Test specifically on your oldest, most degraded documents and your most complex multi-column layouts. Ask for the pilot accuracy report, not a verbal summary.
- AI classification layer above OCR. Evaluate whether the platform includes an AI layer that classifies extracted text into contract fields (party name, effective date, governing law, payment terms, termination clause) without requiring custom template configuration for each document type. Platforms that require per-template setup for every new contract format are not viable at scale.
- Handwriting recognition capability. If your contract archive includes handwritten amendments, signed addenda, or wet-ink dates, confirm the platform’s handwriting OCR capability separately from its typed text accuracy. These require different model training. Ask specifically about handwriting accuracy on legal documents, not on general handwriting benchmarks.
- Contract OCR API and SDK availability. If your organization has existing systems that need to receive extracted contract data (ERP, CRM, procurement platform), evaluate whether the solution offers a contract OCR API for programmatic data export or a contract OCR SDK for deeper integration. OCR data capture services that output only to a proprietary dashboard create data silos that require additional manual export steps to populate other systems. ServiceNow contract management OCR, for example, requires a third-party OCR integration because ServiceNow’s native CLM module does not include document digitization. Purpose-built CLM platforms with native OCR eliminate this overhead.
- Multi-format and multi-language support. Confirm support for every file format in your contract estate (PDF, TIFF, JPEG, DOCX, MSG email attachments) and every language used in your contracts. For multinational organizations with agreements in non-Latin scripts or in multiple European languages, this is a selection filter rather than a nice-to-have.
- Security certifications and data residency. For sensitive contract data, confirm SOC 2 Type II certification, encryption standards, data residency options, and, for government contracts, relevant compliance certifications (FedRAMP, StateRAMP). OCR data services processing legal agreements must meet the same data security standards as the CLM systems they feed.
The best CLM platforms for extracting metadata from scanned contracts in different formats combine all six capabilities in a single integrated system. For a comprehensive evaluation framework, see the best contract management software guide and the CLM implementation roadmap for deployment sequencing recommendations.
How HyperStart CLM combines OCR and AI for contract extraction
HyperStart’s AI contract review software is built on a multi-engine extraction pipeline that combines character recognition with AI classification. The system does not just read a scanned contract; it categorizes what it reads and maps extracted text to structured contract fields without requiring custom template configuration for each document type.
The OCR manager within HyperStart gives legal operations teams full visibility into extraction status, accuracy confidence scores, and review queue volume across every document in the processing pipeline. Extractions above the confidence threshold are accepted automatically. Extractions below the threshold are routed to a human reviewer with the specific low-confidence field flagged, so reviewers spend time on exceptions rather than reviewing every extraction manually.
For enterprise OCR at scale, HyperStart processes multi-format document portfolios through a single ingestion workflow: scanned PDFs, image files (JPEG, TIFF, PNG), Word documents, and email attachments are all accepted in the same batch without requiring document pre-sorting or format conversion. HyperStart’s OCR contracts capability extracts 30+ contract properties per document with 94% AI accuracy, feeding structured data directly into the contract management dashboard for immediate tracking and reporting.
Smart OCR in HyperStart is self-improving: each reviewed and confirmed extraction becomes training data that improves the model’s accuracy on the organization’s specific document portfolio over time. This means extraction accuracy at month six is measurably higher than at month one, without additional configuration or retraining effort from the legal team.
HyperStart also supports organizations using other platforms. For teams evaluating integration options, HyperStart’s contract OCR API allows extraction results to be pushed to ERP systems, CRM platforms, and procurement tools programmatically, without a manual export step. Deploys in 4 weeks with full integration to your existing e-signature, CRM, and document storage systems.
Here is what that means in practice for legal teams:
- 30+ contract properties extracted per document. Party names, effective dates, governing law, payment terms, renewal windows, termination clauses, and obligation schedules, all extracted automatically from scanned contracts without custom template setup.
- 94% AI accuracy with 26-second review. HyperStart reviews and classifies extracted contract data with 94% accuracy. The review that previously required a paralegal spending 90 minutes per contract runs in 26 seconds.
- 48-hour dashboard readiness. Upload your legacy contract archive and HyperStart’s OCR pipeline has your full portfolio organized, searchable, and tracked in 48 hours for a standard digitization project.
- Native CLM integration. Extracted data flows directly into HyperStart’s obligation tracker, renewal alert system, and compliance dashboard without a manual transfer step or a separate OCR vendor relationship.
- Deploys in 4 weeks. Full CLM implementation with OCR, AI review, workflow automation, and integrations completes in a standard 4-week deployment, not a multi-month enterprise project.
Legal teams that digitize their contract estates on HyperStart’s contract management platform recover the visibility, tracking, and compliance capability that exists in their contracts but was previously inaccessible in scanned files and physical archives.